Phân tích RabbitMQ vs Kafka - Chọn hệ thống tin nhắn phù hợp cho nhu cầu của bạn
Bài viết được dịch từ intellisoft.io
Hãy tưởng tượng một không gian trò chuyện sôi động, nơi hàng ngàn người dùng trao đổi thông tin, chia sẻ tin tức và tương tác với sự kiện. Trong môi trường năng động này, hệ thống tin nhắn đóng vai trò như một người điều hành vô hình, đảm bảo mỗi tin nhắn đều đến được người nhận dự định mà không bị trễ hoặc gián đoạn. Tương tự, các ứng dụng phần mềm hiện đại cần có hệ thống tin nhắn mạnh mẽ để xử lý sự giao tiếp phức tạp giữa các thành phần của chúng
RabbitMQ và Apache Kafka là các hệ thống tin nhắn hàng đầu giúp tạo ra sự trao đổi dữ liệu và sự kiện quan trọng trong ngành công nghiệp phát triển phần mềm. Chúng đóng một vai trò quan trọng trong việc phát triển các ứng dụng có khả năng mở rộng và hiệu quả bằng cách cho phép giao tiếp mượt mà giữa các thành phần phần mềm và giúp quản lý các luồng dữ liệu phức tạp. Vậy làm thế nào để bạn quyết định “người chỉ huy” nào phù hợp với ứng dụng của bạn?
Đội ngũ intellisoft có kinh nghiệm rộng lớn trong việc tích hợp các hệ thống tin nhắn vào các kiến trúc ứng dụng phức tạp, chẳng hạn như dự án ZyLAB. Bài viết này sẽ khám phá sự khác biệt giữa Kafka và RabbitMQ, cấu trúc của chúng, các trường hợp sử dụng, và điểm mạnh và yếu. Chúng tôi cũng sẽ cung cấp hướng dẫn về việc chọn hệ thống tin nhắn Kafka hay RabbitMQ dựa trên yêu cầu của ứng dụng của bạn.
Giải thích các khái niệm về Hệ thống tin nhắn Publish/Subscribe (Pub/Sub) và Message Broker
Trước khi đi sâu vào các chi tiết cụ thể của RabbitMQ và Kafka, điều quan trọng là phải hiểu rõ sự khác biệt cơ bản giữa một hệ thống tin nhắn publish/subscribe (pub/sub) và một message broker.
Định nghĩa về Message Broker
Message broker là một trung gian giữa các thành phần ứng dụng, tạo điều kiện cho việc giao tiếp bằng cách chuyển dữ liệu. Chức năng chính của message broker là định tuyến thông tin từ các nhà sản xuất (người gửi tin nhắn) đến các người tiêu dùng (người nhận tin nhắn) dựa trên các quy tắc và logic được định trước. Bằng cách sử dụng một message broker, các ứng dụng có thể tập trung vào các chức năng cốt lõi của chúng trong khi broker xử lý việc giao hàng và định tuyến tin nhắn.
Định nghĩa về Hệ thống tin nhắn Pub/Sub
Mặt khác, một hệ thống tin nhắn publish/subscribe là một mô hình tin nhắn nơi các producers (publishers) gửi tin nhắn mà không chỉ định người nhận. Thay vào đó, họ phân loại tin nhắn vào các topics hoặc channels. Sau đó, consumers (subscribers) biểu thị sự quan tâm đối với các vấn đề cụ thể và nhận thông báo phù hợp với đăng ký của họ. Mô hình tin nhắn này cho phép tách rời giữa producers và consumers, tạo ra sự linh hoạt và khả năng mở rộng hơn trong kiến trúc ứng dụng.
So sánh Message Brokers và Hệ thống tin nhắn Pub/Sub
Cả message brokers và hệ thống tin nhắn pub/sub đều quan trọng trong việc tạo điều kiện cho việc giao tiếp giữa các thành phần ứng dụng. Tuy nhiên, chúng khác nhau về cách định tuyến tin nhắn và xử lý mối quan hệ giữa producers và consumers.
Một message broker tập trung vào việc định tuyến tin nhắn dựa trên các quy tắc được định trước, đảm bảo rằng thông tin đến được consumers phù hợp. Nó có thể hỗ trợ nhiều kiểu nhắn tin khác nhau, chẳng hạn như: - Request/Reply - Point-to-Point - Pub/Sub
Mặt khác, hệ thống tin nhắn “pub/sub” nhấn mạnh việc tách rời giữa các producers và consumers. Nó cho phép nhiều consumers nhận tin nhắn từ một producers duy nhất bằng cách đăng ký cùng một chủ đề hoặc kênh.
Các message broker cung cấp việc giao hàng thông tin đáng tin cậy và đảm bảo các tin nhắn đến được người nhận dự định. Họ cũng có thể cung cấp các tùy chọn duy trì tin nhắn, biến đổi và định tuyến. Tuy nhiên, chúng có thể tạo ra một điểm hỏng duy nhất và có thể trở thành nút thắt hiệu suất nếu không được quản lý đúng cách.
Hệ thống tin nhắn pub/sub cho phép linh hoạt và khả năng mở rộng lớn hơn, cho phép các ứng dụng phát triển mà không ảnh hưởng đến việc giao tiếp giữa các producers và consumers. Tuy nhiên, chúng có thể không cung cấp việc chuyển tiếp tin nhắn đảm bảo hoặc các tính năng định tuyến nâng cao.
Bây giờ chúng ta đã tìm hiểu về sự khác biệt giữa các message broker và hệ thống tin nhắn pub/sub, hãy khám phá RabbitMQ và Kafka một cách chi tiết hơn.
Kafka là gì?
Apache Kafka là một nền tảng streaming với kiến trúc phân tán được thiết kế cho các ứng dụng streaming dữ liệu có khả năng xử lý lớn, chịu lỗi và mở rộng. Ban đầu, nó được phát triển tại LinkedIn và sau đó được mở mã nguồn vào năm 2011. Nhiều tổ chức đã áp dụng rộng rãi Kafka để xây dựng các pipeline dữ liệu thời gian thực, các ứng dụng streaming và kiến trúc dựa trên sự kiện.
Nguồn gốc và lịch sử của Kafka
Jay Kreps, Neha Narkhede và Jun Rao đã tạo ra Kafka để đáp ứng nhu cầu ngày càng tăng về một hệ thống tin nhắn phân tán hiệu suất cao để xử lý lượng dữ liệu lớn được tạo ra bởi cơ sở hạ tầng của LinkedIn. Các phương pháp tin nhắn truyền thống không thể quản lý hiệu quả các luồng dữ liệu thời gian thực, vì vậy họ đã bắt đầu dự án Kafka để cung cấp một nền tảng thống nhất, có khả năng xử lý lớn và độ trễ thấp
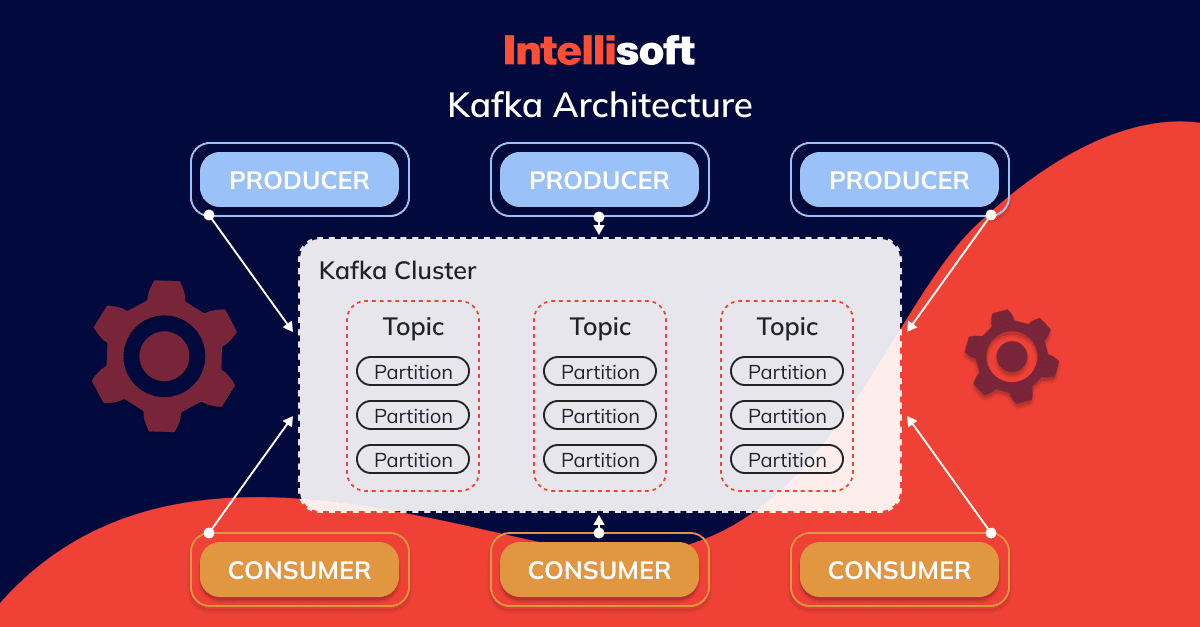
Kiến trúc của Kafka
Các nhà phát triển đã xây dựng kiến trúc của Kafka xung quanh một dịch vụ log commit phân tán và được sao chép, đây là lõi của chức năng tin nhắn của nó. Các thành phần cơ bản của kiến trúc Kafka bao gồm:
-
Producers: Các thực thể gửi tin nhắn đến Kafka.
-
Máy chủ (Brokers): Đây là các nút Kafka lưu trữ và quản lý các tin nhắn đã được xuất bản.
-
Chủ đề (Topics): Các danh mục hoặc kênh mà nhà sản xuất xuất bản tin nhắn.
-
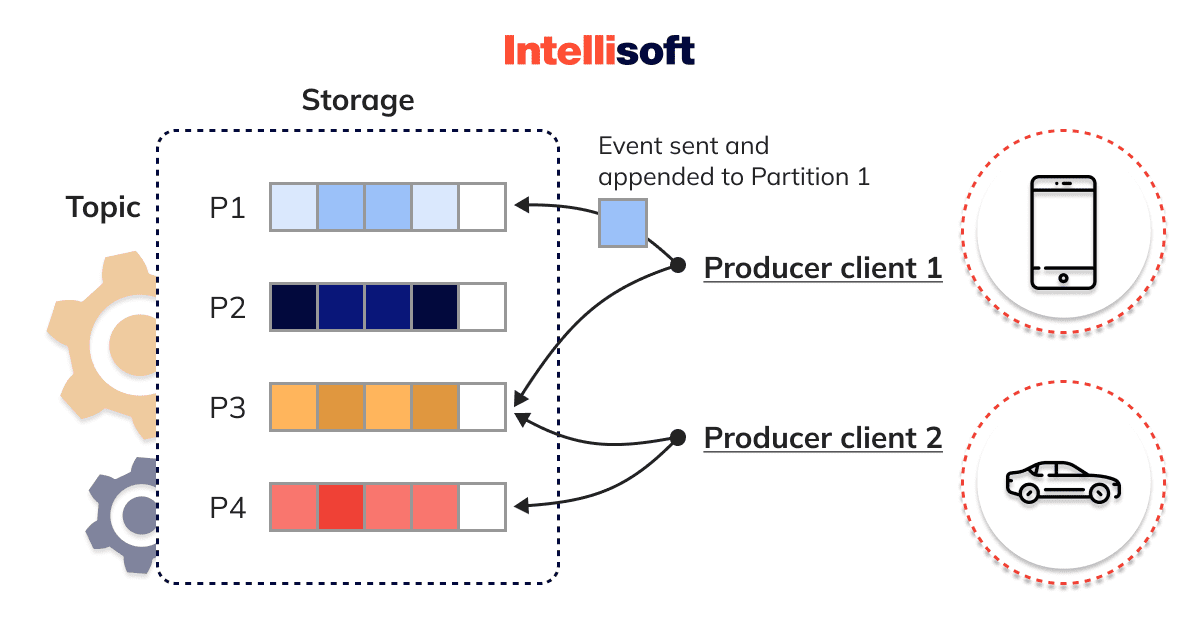
Phân vùng (Partitions): Kafka chia các Topics thành nhiều chuỗi hồ sơ có thứ tự và không thể thay đổi được biết đến là các phân vùng, cho phép song song hóa và tăng khả năng xử lý.
-
Consumers: Các thực thể đọc và xử lý tin nhắn từ Kafka.
-
Cụm (Clusters): Các tập hợp của các máy chủ Kafka làm việc cùng nhau để quản lý và phân phối dữ liệu trên nhiều nút.
-
Consumer Groups: Các tập hợp của Consumer trong Kafka hợp tác để tiêu thụ dữ liệu từ một hoặc nhiều chủ đề.
-
Replicas: Các bản sao của một phân vùng Kafka được phân phối trên nhiều máy chủ.
-
Leaders: Các máy chủ được chỉ định trong một cụm Kafka chịu trách nhiệm xử lý tất cả các yêu cầu đọc và ghi cho một phân vùng cụ thể.
-
Followers: Các máy chủ trong một cụm Kafka sao chép một cách thụ động dữ liệu của người dẫn đầu cho một phân vùng nhất định, sẵn sàng thay thế làm người dẫn đầu mới nếu người dẫn đầu hiện tại gặp sự cố.
Kafka cung cấp một sự cam kết về độ bền mạnh mẽ vì các tin nhắn được lưu trữ trên đĩa và được sao chép trên nhiều brokers. Cách tiếp cận này đảm bảo khả năng chịu lỗi cao và giảm thiểu việc mất mát dũ liệu khi 1 node chết.
RabbitMQ là gì?
RabbitMQ là một message broker mã nguồn mở, sử dụng Advance Message Queue Tool Protocol (AMQP). Được phát hành vào năm 2007, RabbitMQ đã được phổ biến rộng rãi nhờ sự linh hoạt, độ tin cậy và dễ sử dụng. Bằng cách hoạt động như một message broker and queueing server, RabbitMQ cho phép các ứng dụng đa dạng trao đổi dữ liệu thông qua giao thức chuẩn hoặc các tác vụ xếp hàng để xử lý bởi người tiêu dùng phân tán. Hàng chờ của RabbitMQ có thể lưu trữ task, cho phép broker có thể cân bằng tải và phân phối task.
Nguồn gốc và lịch sử của RabbitMQ
Rabbit Technologies Ltd, một công ty được thành lập bởi Alexis Richardson và Matthias Radestock, đã phát triển RabbitMQ để tạo ra 1 broker hiệu năng cao, có thể mở rộng và dễ sử dụng, đồng thời có thể hỗ trợ nhiều kiểu tin nhắn khác nhau, và tích hợp đa nền tảng, đa ngôn ngữ.
Kiến trúc của RabbitMQ
Kiến trúc của RabbitMQ bao gồm một số thành phần chính hỗ trợ việc gửi và định tuyến tin nhắn:
- Producers: các đối tượng gửi tin nhắn đến RabbitMQ.
- Exchanges: Các thành phần này chịu trách nhiệm nhận tin nhắn từ Producers và định tuyến chúng đến hàng đợi thích hợp dựa trên các quy tắc được xác định trước.
- Queues: Bộ đệm lưu trữ tin nhắn cho đến khi người tiêu dùng sử dụng chúng.
- Bindings: Các quy tắc xác định mối quan hệ giữa các trao đổi và hàng đợi, xác định việc định tuyến các tin nhắn.
- Consumers: Các đối tượng nhận và xử lý tin nhắn từ RabbitMQ
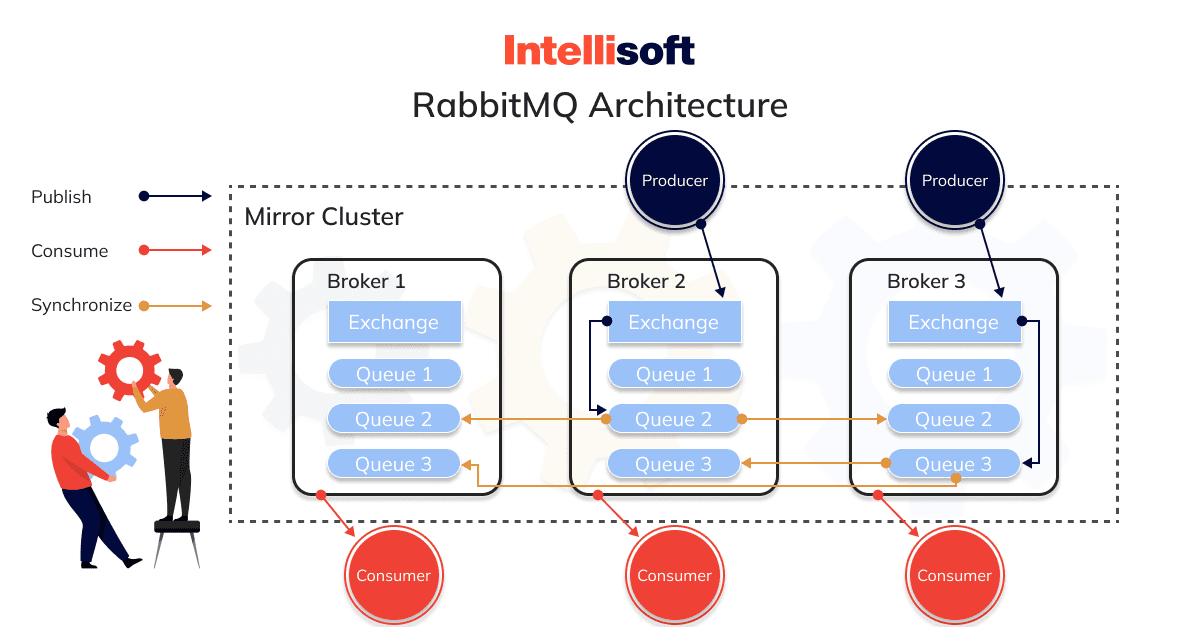
RabbitMQ được biết đến với khả năng định tuyến linh hoạt, dễ sử dụng và hỗ trợ nhiều giao thức như: AMQP, MQTT, và STOMP.
Kafka được sử dụng để làm gì?
Kafka có nhiều trường hợp sử dụng khác nhau, khiến nó trở thành lựa chọn phổ biến cho nhiều loại ứng dụng khác nhau. Một số trường hợp sử dụng Kafka phổ biến bao gồm:
-
Data Streaming
-
Phân tích dữ liệu thời gian thực
-
Hệ thống phân tán
Kafka trong Data Streaming và phân tích thời gian thực
Data Streaming là một trong những trường hợp sử dụng chính của Kafka, trong đó nó hoạt động như một hệ thống nhắn tin có khả năng mở rộng cao và có khả năng chịu lỗi cho phép xử lý dữ liệu theo thời gian thực. Khả năng xử lý các luồng dữ liệu thông lượng cao của Kafka khiến nó trở nên lý tưởng cho việc nhập và xử lý khối lượng dữ liệu lớn theo thời gian thực. Do tính năng này, Kafka rất phù hợp cho các ứng dụng tổng hợp nhật ký, phân tích thời gian thực và lưu trữ dữ liệu.
Kafka trong hệ thống phân tán
Bạn cũng có thể sử dụng Kafka trong các hệ thống phân tán làm backbone để liên lạc giữa các dịch vụ và thành phần. Kafka đảm bảo rằng các hệ thống phân tán có thể hoạt động hiệu quả và đáng tin cậy bằng cách cung cấp nền tảng nhắn tin có tính sẵn sàng cao, có khả năng chịu lỗi và có khả năng mở rộng. Nó hoạt động để xây dựng kiến trúc microservices, phương pháp tiếp cận hướng sự kiện và các ứng dụng phân tán quy mô lớn khác.
Lợi ích của việc sử dụng Kafka
Kafka cung cấp một số lợi ích khiến nó trở thành sự lựa chọn hấp dẫn cho nhiều ứng dụng khác nhau:
-
Lưu lượng cao: Kafka có thể xử lý hàng triệu sự kiện mỗi giây, khiến nó phù hợp với các ứng dụng phân tích thời gian thực và truyền dữ liệu quy mô lớn.
-
Khả năng mở rộng: Kafka có thể nhanh chóng mở rộng quy mô theo chiều ngang bằng cách thêm nhiều brokers hơn vào một cluster, cho phép nó đáp ứng khối lượng công việc ngày càng tăng.
-
Độ bền: Kafka lưu trữ tin nhắn trên đĩa và sao chép chúng trên nhiều brokers, đảm bảo khả năng chịu lỗi cao và độ bền dữ liệu.
-
Độ trễ thấp: Kafka cung cấp khả năng gửi tin nhắn có độ trễ thấp, phù hợp với các ứng dụng thời gian thực yêu cầu thời gian phản hồi nhanh.
-
Khả năng chịu lỗi: Kafka cung cấp một khả năng quan trọng để chống lại việc các node hoặc server trong cụm bị lỗi. Nó đảm bảo hiệu suất ổn định, không bị gián đoạn, bảo vệ tính toàn vẹn của hệ thống và ngăn ngừa sự gián đoạn có thể xảy ra.
-
Xử lý hàng loạt: Khả năng của Kafka mở rộng sang các kịch bản xử lý hàng loạt, cạnh tranh với các giải pháp ETL truyền thống. Khả năng lưu giữ các thông báo của nó cho phép nó thích ứng với các trường hợp sử dụng đa dạng, thể hiện tính linh hoạt và tiện ích vượt trội trong các bối cảnh xử lý dữ liệu khác nhau.
RabbitMQ được sử dụng để làm gì?
RabbitMQ, giống như Kafka, có nhiều trường hợp sử dụng nhờ tính linh hoạt và hỗ trợ cho nhiều mẫu tin nhắn khác nhau. Một số trường hợp sử dụng RabbitMQ phổ biến bao gồm:
-
Tích hợp ứng dụng
-
Messaging
-
Microservices Architecture
-
Critical APIs
-
Xử lý PDF
-
Xử lý sao lưu cơ sở dữ liệu
RabbitMQ trong tích hợp ứng dụng và Messaging
Các nhà phát triển thường sử dụng RabbitMQ để tích hợp ứng dụng và nhắn tin, nơi nó hoạt động như một nhà môi giới tin nhắn linh hoạt và đáng tin cậy, tạo điều kiện giao tiếp giữa các thành phần ứng dụng khác nhau.Nó hỗ trợ cho nhiều mẫu và giao thức nhắn tin giúp nó phù hợp để tích hợp các hệ thống khác nhau, cho phép các ứng dụng trao đổi dữ liệu và sự kiện theo cách tách rời.
RabbitMQ trong kiến trúc Microservices
Bạn cũng có thể sử dụng RabbitMQ trong các kiến trúc microservice. Nó hoạt động như lớp giao tiếp giữa các microservice khác nhau. Bằng cách cung cấp nền tảng nhắn tin đáng tin cậy và có thể mở rộng, RabbitMQ cho phép các microservice trao đổi dữ liệu và sự kiện một cách hiệu quả, đảm bảo hoạt động trơn tru trong các hệ thống phức tạp.
Lợi ích của việc sử dụng RabbitMQ
RabbitMQ cung cấp một số lợi ích khiến nó trở thành lựa chọn phổ biến cho các ứng dụng khác nhau:
-
Linh hoạt: RabbitMQ hỗ trợ nhiều mẫu và giao thức nhắn tin, giúp nó có thể thích ứng với nhiều tình huống ứng dụng khác nhau.
-
Dễ sử dụng: RabbitMQ được biết đến với thiết kế thân thiện với người dùng và tài liệu toàn diện, giúp bạn dễ dàng tìm hiểu và triển khai.
-
Độ tin cậy: RabbitMQ cung cấp khả năng gửi tin nhắn đáng tin cậy, đảm bảo tin nhắn đến được với người nhận dự định ngay cả khi có lỗi.
-
Khả năng định tuyến phong phú: Cơ chế trao đổi và ràng buộc của RabbitMQ cho phép định tuyến tin nhắn nâng cao, cho phép tạo ra các kiến trúc ứng dụng phức tạp.
-
Tách rời: Hệ thống của bên thứ ba có thể dễ dàng truy cập và tương tác với tin nhắn, bất kể người gửi ban đầu là ai. Ưu điểm này cho phép tái sử dụng hiệu quả các thông báo này trong nhiều dự án.
-
Redundancy: Một trong những điểm mạnh chính của RabbitMQ nằm ở khả năng lưu trữ tin nhắn một cách an toàn trong hàng đợi. Điều này đảm bảo rằng mỗi tin nhắn vẫn được bảo quản an toàn cho đến khi nó được xử lý và xác nhận đầy đủ, nhờ đó nâng cao độ tin cậy và ngăn ngừa mất dữ liệu.
Kafka vs RabbitMQ: Sự khác biệt
Sự khác biệt giữa Kafka và RabbitMQ là gì? Mặc dù cả RabbitMQ và Kafka đều là những hệ thống nhắn tin phổ biến nhưng chúng có những đặc điểm khác nhau khiến chúng phù hợp với nhiều ứng dụng khác nhau. Hãy so sánh Apache Kafka và RabbitMQ dựa trên các khía cạnh như:
-
Hiệu năng
-
Khả năng mở rộng
-
Độ bền của tin nhắn
-
Độ tin cậy
-
Dễ sử dụng và thiết lập
-
Cộng đồng hỗ trợ và hệ sinh thái
-
Các mẫu định tuyến và nhắn tin
-
Giao thức, thư viện và các ngôn ngữ hỗ trợ
-
Độ trễ
| Tính năng | RabbitMQ | Apache Kafka |
|---|---|---|
| Mô tả | Một broker tin nhắn an toàn, đáng tin cậy để sử dụng chung | Bus tin nhắn được thiết kế riêng cho luồng dữ liệu khối lượng lớn và phát lại tin nhắn |
| Mục đích chính | Tạo điều kiện giao tiếp và tích hợp trong và giữa các ứng dụng; lý tưởng cho các nhiệm vụ lâu dài và các công việc nền đáng tin cậy | Cung cấp nền tảng để lưu trữ, truy cập và phân tích dữ liệu truyền phát |
| Giấy phép | Open Source: Mozilla Public License | Open Source: Apache License 2.0 |
| Implementation | Erlang | Scala (JVM) |
| Phát hành lần đầu | 2007 | 2011 |
| Vòng đời của message | Lưu trữ tin nhắn cho đến khi được người nhận xác nhận | Giữ lại tin nhắn với tùy chọn xóa sau một khoảng thời gian nhất định |
| Gửi lại message | Không hỗ trợ | Có hỗ trợ |
| Định tuyến message | Cho phép định tuyến linh hoạt với thông tin được trả về consumer nodes | Việc định tuyến phải được xử lý thông qua các topic riêng biệt; định tuyến linh hoạt không được hỗ trợ |
| Độ ưu tiên của message | Có hỗ trợ | Không hỗ trợ |
| Giám sát | Giao diện người dùng tích hợp có sẵn để theo dõi | Cần có các công cụ của bên thứ ba như CloudKarafka hoặc Confluent để giám sát |
| Khả năng tương thích với các ngôn ngữ lập trình | Hỗ trợ hầu hết các ngôn ngữ lập trình | Tương thích với hầu hết các ngôn ngữ lập trình |
| Bảo mật xác thực | Xác thực tiêu chuẩn và hỗ trợ OAuth2 | Cung cấp hỗ trợ cho Kerberos, OAuth2 và xác thực tiêu chuẩn |
So sánh hiệu năng
Sự khác biệt giữa Kafka và RabbitMQ là ở hiệu năng. Kafka được biết đến với việc có lưu lượng cao và khả năng xử lý hàng triệu sự kiện mỗi giây. Điều này giúp cho Kafka phù hợp với các ứng dụng phân tích dữ liệu thời gian thực và truyền dữ liệu quy mô lớn. RabbitMQ, mặc dù kém hiệu quả hơn Kafka về lưu lượng, vẫn có thể xử lý nhiều tin nhắn và quá đủ cho nhiều tình huống ứng dụng.
So sánh khả năng mở rộng
Một sự khác biệt nữa giữa Kafka và RabbitMQ là khả năng mở rộng. Cả 2 đều có khả năng mở rộng. Kafka đạt được khả năng mở rộng thông qua phân vùng và chia tỷ lệ theo chiều ngang bằng cách thêm nhiều nhà môi giới hơn vào một cụm. RabbitMQ cũng có thể mở rộng quy mô theo chiều ngang bằng cách nhóm nhiều node RabbitMQ lại với nhau, nhưng nó dựa vào việc phân chia tin nhắn để phân phối tin nhắn trên các node. Mặc dù cả hai hệ thống đều có khả năng mở rộng nhưng nhìn chung Kafka có lợi thế hơn khi xử lý khối lượng công việc lớn nhờ khả năng phân vùng của nó.
Độ bền và độ tin cậy của tin nhắn
Kafka cung cấp sự đảm bảo về độ bền cao, vì các tin nhắn được lưu giữ trên đĩa và được sao chép trên nhiều brokers. Nó đảm bảo khả năng chịu lỗi cao và mất dữ liệu tối thiểu trong trường hợp node bị lỗi. RabbitMQ cũng hỗ trợ tính bền vững và sao chép tin nhắn, nhưng sự đảm bảo về độ bền của nó phụ thuộc vào cấu hình, xác nhận và nhìn nhận của publisher.
Dễ sử dụng và thiết lập
Các developers thường khen ngợi RabbitMQ vì tính dễ sử dụng, tài liệu toàn diện và giao diện quản lý thân thiện với người dùng. Nó làm cho việc thiết lập, tìm hiểu và quản lý tương đối đơn giản. Mặt khác, Kafka khó tiếp cận hơn dành cho người mới và có thể khó thiết lập và kiểm soát hơn do tính chất phân tán và các tùy chọn cấu hình phức tạp hơn.
Cộng đồng và hệ sinh thái
Cả RabbitMQ và Kafka đều được hưởng lợi từ sự hỗ trợ cộng đồng mạnh mẽ và hệ sinh thái rộng lớn. Các hệ sinh thái này bao gồm nhiều plugin, thư viện và phần tích hợp khác nhau được thiết kế riêng cho nhiều nền tảng và ngôn ngữ lập trình. Sự ủng hộ mạnh mẽ từ cộng đồng tương ứng của họ góp phần vào sự phát triển và cải tiến liên tục của các hệ thống nhắn tin này. Do đó, các nhà phát triển có thể dựa vào tài liệu toàn diện, diễn đàn hỗ trợ và tính sẵn có của các đóng góp nguồn mở, giúp nâng cao năng lực tiếp cận và khả năng thích ứng của RabbitMQ và Kafka trong việc đáp ứng nhu cầu của các ứng dụng và trường hợp sử dụng đa dạng.
Định tuyến và mẫu tin nhắn
RabbitMQ được biết đến với khả năng định tuyến phong phú và hỗ trợ nhiều kiểu nhắn tin khác nhau, bao gồm request/reply, point-to-point, and publish/subscribe. Các cơ chế trao đổi và ràng buộc này cho phép định tuyến tin nhắn nâng cao, có thể hữu ích trong các kiến trúc ứng dụng phức tạp.
Kafka chủ yếu hỗ trợ mẫu tin nhắn publish/subscribe, tập trung vào truyền dữ liệu thông lượng cao. Mặc dù khả năng định tuyến của Kafka kém hơn so với RabbitMQ, nhưng cơ chế phân vùng của nó cho phép thực hiện song song và tăng thông lượng.

Hỗ trợ giao thức, thư viện và ngôn ngữ
Kafka hỗ trợ nhiều ngôn ngữ lập trình và thư viện. Nó có các ứng dụng khách tích hợp sẵn mà bạn có thể bổ sung bằng nhiều ứng dụng do cộng đồng đóng góp. Các ứng dụng này có sẵn cho Java và Scala, bao gồm thư viện Kafka Streams nâng cao, Go, Python, C/C++ và nhiều ngôn ngữ khác, ngoài API REST. Hơn nữa, Kafka Connect có hàng trăm trình kết nối dựng sẵn để tích hợp liền mạch với các hệ thống và ứng dụng bên ngoài.
RabbitMQ tương thích với nhiều thư viện và ngôn ngữ lập trình, bao gồm Java, Go, .NET, v.v. Nó cũng hỗ trợ các giao thức như AMQP 0.9.1, AMQP 1.0, STOMP và MQTT. Ngoài ra, nhiều thư viện client có sẵn cho các môi trường và ngôn ngữ lập trình đa dạng.
Độ trễ
Sự khác biệt giữa Kafka và RabbitMQ còn nằm ở độ trễ. Kafka được thiết kế để gửi tin nhắn có độ trễ thấp, phù hợp với các ứng dụng thời gian thực yêu cầu thời gian phản hồi nhanh. RabbitMQ, mặc dù chậm hơn Kafka về độ trễ nhưng vẫn cung cấp khả năng gửi tin nhắn có độ trễ thấp và phù hợp cho hầu hết các tình huống ứng dụng.
Ưu và nhược điểm của Kafka
Chúng ta hãy xem xét kỹ hơn những điểm mạnh và điểm yếu của Kafka, nêu bật những ưu điểm chính và những hạn chế tiềm ẩn của nó để giúp bạn hiểu rõ hơn khi nào và ở đâu nó tỏa sáng.
Ưu điểm
-
Độ trễ thấp: Kafka cung cấp độ trễ thấp, thường đạt tới 10 mili giây. Tốc độ này đạt được bằng cách tách tin nhắn, cho phép consumer truy cập và xử lý chúng bất cứ khi nào họ chọn.
-
Lưu lượng cao và khả năng mở rộng: Kafka được thiết kế để truyền dữ liệu quy mô lớn, hiệu suất cao và có thể xử lý hiệu quả hàng triệu sự kiện mỗi giây. Kiến trúc phân tán của nó cho phép nó mở rộng quy mô theo chiều ngang bằng cách thêm nhiều nhà môi giới hơn, khiến nó phù hợp để xử lý khối lượng dữ liệu lớn.
-
Khả năng chịu lỗi và độ bền: Kafka đảm bảo độ bền của dữ liệu bằng cách sao chép tin nhắn trên nhiều node brokers. Nếu một broker không thành công, một broker khác trong cụm có thể tiếp quản và tiếp tục xử lý các tin nhắn, cung cấp khả năng chịu lỗi và đảm bảo tính khả dụng của dữ liệu.
-
Lưu trữ dữ liệu dựa trên log: Kafka sử dụng hệ thống lưu trữ dựa trên log, cho phép lưu trữ và xử lý các luồng dữ liệu một cách tuần tự và không thay đổi. Cách tiếp cận này có hiệu quả cao đối với dữ liệu chuỗi thời gian và các ứng dụng hướng sự kiện, hỗ trợ phân tích dữ liệu theo thời gian thực.
-
Luồng xử lý: Kafka cung cấp khả năng xử lý luồng gốc thông qua thư viện Kafka Streams, cho phép các nhà phát triển xây dựng các ứng dụng xử lý dữ liệu thời gian thực mạnh mẽ mà không cần khung hoặc công cụ bổ sung.
Nhược điểm
-
Độ phức tạp: Kiến trúc và cấu hình của Kafka có thể phức tạp và đầy thách thức đối với người mới. Quá trình học tập của nó có thể khó khăn đối với những người cần làm quen nhiều hơn với các hệ thống phân tán và các khái niệm lưu trữ dựa trên log.
-
Hạn chế định tuyến message: Kafka chủ yếu dựa vào khả năng định tuyến theo topic và partition. Mặc dù phương pháp này phù hợp với nhiều trường hợp sử dụng nhưng nó có thể không linh hoạt bằng khả năng định tuyến được cung cấp bởi các hệ thống nhắn tin khác như RabbitMQ.
-
Thiếu tích hợp độ ưu tiên message: Các nhà phát triển không thiết kế Kafka để cung cấp hỗ trợ tích hợp cho việc ưu tiên tin nhắn. Nó xử lý tin nhắn theo thứ tự nhận được, điều này có thể không lý tưởng cho các ứng dụng yêu cầu mức độ ưu tiên dựa trên nội dung tin nhắn hoặc các yếu tố khác.
-
Hiệu suất giảm: Brokers và consumers nén và giải nén luồng dữ liệu có thể ảnh hưởng đến hiệu suất và thông lượng của Kafka. Quá trình này ảnh hưởng đến hiệu quả của Kafka và ảnh hưởng đến khả năng xử lý dữ liệu tổng thể của nó.